
为什么分库分表?
说在前边
今天是《ShardingSphere5.x分库分表原理与实战》系列的开篇文章,之前写过几篇关于分库分表的文章反响都还不错,到现在公众号:程序员小富后台不断的有人留言、咨询分库分表的问题,我也没想到大家对于分库分表的话题会这么感兴趣,可能很多人的工作内容业务量较小很难接触到这方面的技能。这个系列在我脑子里筹划了挺久的,奈何手说啥也不干活,就一直拖到了现在。
其实网上关于分库分表相关的文章很多,但我还是坚持出这个系列,主要是自己学习研究,顺便给分享,对于一个知识,不同的人从不同的角度理解的不尽相同。
网上的资料看似很多,不过值得学有价值的得仔细挑,很多时候在筛选甄别的过程中,逐渐的磨灭了本就不高的学习热情。搬运抄袭雷同的东西太多,而且知识点又都比较零碎,很少有细致的原理实战案例。对新手来说妥妥的从入门到放弃,即便有成体系的基本上几篇后就断更了(希望我不会吧!)。
我不太喜欢堆砌名词概念,熟悉我的朋友不难发现,我的文章从来都是讲完原理紧跟着来一波实战操作。学习技术原理必须配合实操巩固一下,不然三天半不到忘得干干净净,纯纯的经验之谈。
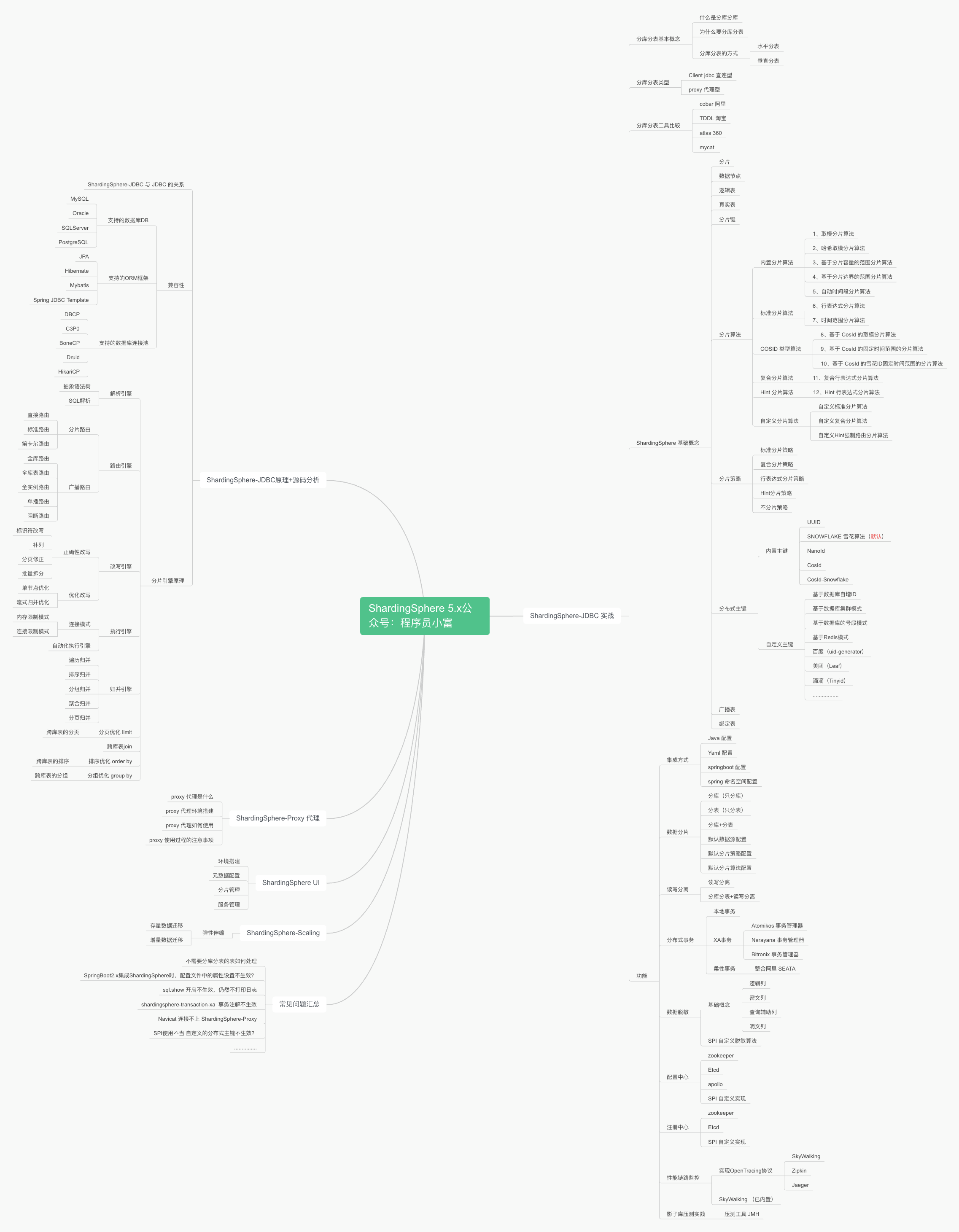
上图是我初步罗列的ShardingSphere提纲,在官网文档基础上补充了很多基础知识,这个系列会用几十篇文章,详细的梳理分库分表基础理论,手把手的实战ShardingSphere 5.X框架的功能和解读源码,以及开发中容易踩坑的点,每篇附带代码案例demo,旨在让新手也能看的懂,后续系列完结全部内容会整理成PDF分享给大家,期待一下吧!

话不多说,咱们这就进入正题~
不急于上手实战ShardingSphere框架,先来复习下分库分表的基础概念,技术名词大多晦涩难懂,不要死记硬背理解最重要,当你捅破那层窗户纸,发现其实它也就那么回事。
什么是分库分表
分库分表是在海量数据下,由于单库、表数据量过大,导致数据库性能持续下降的问题,演变出的技术方案。
分库分表是由分库和分表这两个独立概念组成的,只不过通常分库与分表的操作会同时进行,以至于我们习惯性的将它们合在一起叫做分库分表。
通过一定的规则,将原本数据量大的数据库拆分成多个单独的数据库,将原本数据量大的表拆分成若干个数据表,使得单一的库、表性能达到最优的效果(响应速度快),以此提升整体数据库性能。
为什么分库分表
单机数据库的存储能力、连接数是有限的,它自身就很容易会成为系统的瓶颈。当单表数据量在百万以里时,我们还可以通过添加从库、优化索引提升性能。
一旦数据量朝着千万以上趋势增长,再怎么优化数据库,很多操作性能仍下降严重。为了减少数据库的负担,提升数据库响应速度,缩短查询时间,这时候就需要进行分库分表。
为什么需要分库?
容量
我们给数据库实例分配的磁盘容量是固定的,数据量持续的大幅增长,用不了多久单机的容量就会承载不了这么多数据,解决办法简单粗暴,加容量!
连接数
单机的容量可以随意扩展,但数据库的连接数却是有限的,在高并发场景下多个业务同时对一个数据库操作,很容易将连接数耗尽导致too many connections报错,导致后续数据库无法正常访问。
可以通过max_connections查看MySQL最大连接数。
show variables like '%max_connections%'

将原本单数据库按不同业务拆分成订单库、物流库、积分库等不仅可以有效分摊数据库读写压力,也提高了系统容错性。
为什么需要分表?
做过报表业务的同学应该都体验过,一条SQL执行时间超过几十秒的场景。
导致数据库查询慢的原因有很多,SQL没命中索引、like扫全表、用了函数计算,这些都可以通过优化手段解决,可唯独数据量大是MySQL无法通过自身优化解决的。慢的根本原因是InnoDB存储引擎,聚簇索引结构的 B+tree 层级变高,磁盘IO变多查询性能变慢,详细原理自行查找一下,这里不用过多篇幅说明。
阿里的开发手册中有条建议,单表行数超500万行或者单表容量超过2GB,就推荐分库分表,然而理想和实现总是有差距的,阿里这种体量的公司不差钱当然可以这么用,实际上很多公司单表数据几千万、亿级别仍然不选择分库分表。

什么时候分库分表
技术群里经常会有小伙伴问,到底什么情况下会用分库分表呢?
分库分表要解决的是现存海量数据访问的性能瓶颈,对持续激增的数据量所做出的架构预见性。
是否分库分表的关键指标是数据量,我们以fire100.top这个网站的资源表 t_resource为例,系统在运行初始的时候,每天只有可怜的几十个资源上传,这时使用单库、单表的方式足以支持系统的存储,数据量小几乎没什么数据库性能瓶颈。
但某天开始一股神秘的流量进入,系统每日产生的资源数据量暴增至十万甚至上百万级别,这时资源表数据量到达千万级,查询响应变得缓慢,数据库的性能瓶颈逐渐显现。
以MySQL数据库为例,单表的数据量在达到亿条级别,通过加索引、SQL调优等传统优化策略,性能提升依旧微乎其微时,就可以考虑做分库分表了。
既然MySQL存储海量数据时会出现性能瓶颈,那么我们是不是可以考虑用其他方案替代它?比如高性能的非关系型数据库MongoDB?
可以,但要看存储的数据类型!
现在互联网上大部分公司的核心数据几乎是存储在关系型数据库(MySQL、Oracle等),因为它们有着NoSQL如法比拟的稳定性和可靠性,产品成熟生态系统完善,还有核心的事务功能特性,也是其他存储工具不具备的,而评论、点赞这些非核心数据还是可以考虑用MongoDB的。